Système de fichier : l'émergence de btrfs ?
Présentation des fonctionnalités offertes par Btrfs, comparaison de ses performances avec d’autres systèmes de fichiers et exemples d’utilisation
Parmi les systèmes de fichiers actuels, Btrfs (B-tree File System, à prononcer « Butter-FS ») commence à se faire un nom. S’il est encore en phase de développement, il doit à terme remplacer Ext4 (utilisé par défaut sur la plupart des distributions GNU/Linux) et offrir une alternative à ZFS. Nous allons donc détailler les fonctionnalités offertes par Btrfs, comparer ses performances avec d’autres systèmes de fichiers et enfin donner des exemples d’utilisation.
Btrfs et les autres systèmes de fichiers
Traditionnellement, les systèmes GNU/Linux utilisent les systèmes de fichiers de la famille des Ext. Actuellement, Ext4 est la version utilisée par défaut sur beaucoup de système, mais est considérée par ses développeurs comme une version de transition en attendant l’arrivée d’un successeur plus « révolutionnaire » : Btrfs.
Le projet Btrfs voit le jour fin 2007 et a pour but de créer un système de fichier combinant toutes les couches utilisées par Ext4 (mdadm, lvm, fs…) en un produit unique. Ainsi, le système de fichiers est capable de gérer tous les cas d’utilisation sans recquérir de logiciels externes plus ou moins bien implémentés. L’un des buts de Btrfs est de proposer les mêmes fonctionnalités que ZFS, tout en étant mieux intégrés au sein des noyaux Linux. Le projet est placé sous licence GNU GPL, et est développé conjointemenet par plusieurs grandes entreprises (Intel, Linux Fondation, Oracle, Red Hat, Suse, etc.) et par des développeurs particuliers.
Un point sur ZFS
ZFS est actuellement l’un des systèmes de fichiers les plus performants. Il offre toutes les fonctionnalités de Btrfs, et d’autres non encore implémentée dans Btrfs. Cependant, il souffre de deux inconvénients majeurs : sa licence le rend incompatible avec le noyau Linux, ce qui rend son implémentation officielle dans les projets GNU/Linux impossible, et il consomme beaucoup de mémoire (surtout sur les systèmes GNU/Linux, en partie du fait de sa mauvaise intégration). Ainsi, s’il est possible d’utiliser ZFS ou un portage avec GNU/Linux, il est en pratique délicat de maintenir une telle installation, ce qui rend l’usage de ZFS impossible en production sur des parcs GNU/Linux.
Btrfs, un projet toujours en développement
Btrfs est actuellement en phase active de développement. Il est conseillé de toujours maintenir son noyau Linux à jour si on souhaite profiter de toutes les fonctionnalités et des bonnes performances de Btrfs. Cependant, un certain nombre des fonctionnalités sont considérées stables, notamment les instantannés et certains RAID ; par ailleurs, les risques de problème important amenant une perte de données sont considérés comme faibles si l’utilisateur ne se sert pas des outils considérés comme non-stables.
Btrfs est supporté par beaucoup des distributions les plus populaires : Debian, Ubuntu, OpenSuSE (qui en a fait son système de fichier par défaut depuis OpenSuSE 13.2), etc. Par ailleurs, deux entreprises proposent du support pour Btrfs : SUSE Enterprise Linux (depuis SLES11 SP2) et Oracle (depuis Oracle Linux 5).
Btrfs : la base
Structure
Btrfs utilise une structure de type arbre B pour stocker les métadonnées. Un arbre B a l’avantage d’être toujours équilibré ce qui garantit un temps de recherche et d’insertion en log base B de la hauteur de l’arbre. Toutes les données ne sont pas stockées dans le même arbre, Btrfs utilise plusieurs arbres pour stocker séparément :
- Les racines des autres arbres
- les parties des périphériques alloués et leurs types
- les extents alloués pour le système et leur compteur de référence
- les sommes de contrôle (plusieurs arbres distincts)
- les informations sur le système de fichiers, les fichiers et les répertoires
Les informations sont classées par clefs dans l’arbre, les données ne sont situées que dans les feuilles, comme dans un arbre de type B+, mais sans les liens entre les feuilles. Chaque clef est l’association d’un identifiant d’objet, d’un type et d’un offset, sous la forme [id, type, offset].
Dans le cas des fichiers, l’identifiant d’objet correspond au numéro d’inode. Chacune des informations spécifiques à un inode a le même numéro inode comme identifiant, mais avec un type et un offset différent. Ainsi toutes les métadonnées en lien avec un inode sont stockées proches les unes des autres dans l’arbre.
Un des grands avantages de btrfs est la possibilité de stocker les petits fichiers entièrement dans les feuilles, ce qui permet de minimiser l’espace utilisée, l’allocation dans les feuilles n’étant pas faite par blocs. La lecture et l’écriture de petits fichiers se fait rapidement car les données sont ainsi directement dans l’arbre, ce qui diminue le nombre de requêtes et les temps d’accès aux données.
Btrfs fonctionne avec des volumes et des fichiers de taille inférieure ou égale à 16 EiB, et accepte un nombre illimité de fichiers. Ceux-ci ont un nom allant jusqu’à 255 caractères, et ne contenant pas les caractères « / » et « \0 ».
Mode d’allocation : l’extent
Les anciens systèmes de fichiers (jusqu’à Ext3) utilisent l’adressage par blocs : le support de stockage est découpé en blocs de taille fixe (généralement 512, 1024 ou 2048ko), qui sont alloués aux fichiers en cours d’écriture. Comme les fichiers sont souvent plus grands que les blocs, il est nécessaire d’allouer plusieurs blocs pour un même fichier, ce qui améne la fragmentation et la gestion des différents blocs par l’intermédiaire des métadonnées, qui peuvent être de tailles importantes et dont l’écriture peut ralentir le système.
Les sytèmes de fichiers plus récents (entre autes Ext4, ZFS, Btrfs) se basent sur la notion d’extent : l’espace de stockage n’est pas alloué sous la forme de blocs, mais d’ensembles contigus de blocs, ce qui réduit grandement la fragmentation. De plus, la gestion des métadonnées est simplifiée, car au lieu d’une liste de blocs, il suffit de sauvegarder la taille de la portion de fichier et le numéro du premier bloc de données.
Lors de l’écriture d’un fichier sur le disque, un extent lui est alloué. Par la suite, si le fichier est modifié, les nouvelles données sont ajoutées à la suite, dans le même extent ; quand celui-ci est plein, un nouvel extent est alloué. Cette méthode permet de réduire les temps d’accès pour les gros fichiers, et rend les opérations modifiant les métadonnées (par exemple la suppression) beaucoup plus rapides, car moins de métadonnées sont à modifier.
Copie sur écriture
La copie sur écriture (souvent désignée par son acronyme COW, pour Copy-On-Write) est une optimisation utilisée principalement en base de donnée et dans certains systèmes de fichiers (notamment ZFS et Btrfs). Son principe est le suivant : si plusieurs processus demandent l’accès à la même ressource, le système de fichier leur fournit à tous le même pointeur, sans que la ressource ne soit dupliquée. En cas d’écriture de la part de l’un des processus, une « copie privée » de la ressource est effectuée et est allouée au processus ayant initié l’écriture, le tout de manière transparente.
La copie sur écriture apporte deux améliorations à Btrfs. Premièrement, dans le cadre d’une utilisation classique, elle permet de diminuer l’utilisation de la mémoire cache, car les ressources utilisées n’y sont copiées qu’une seule fois même si plusieurs processus y accédent, jusqu’à ce que des modifications soient apportées par un processus. L’autre utilisation se fait en parallèle avec les instantannées (voir section suivante).
Commandes de base
La création d’une partition Btrfs se fait classiquement :
root@debian:~# mkfs.btrfs *dev*Cette commande admet un grand nombre d’options, listées sur le site officiel. Nous allons détailler plusieurs de ces options par la suite.
Btrfs propose aussi la commande btrfs (manuel officiel), qui permet d’effectuer plusieurs actions sur les systèmes de fichiers Btrfs. Nous allons en aborder plusieurs dans la suite lorsqu’elles concerneront des fonctionnalités intéressantes ; cependant, quelques commandes simples méritent d’être citées.
Ainsi, Btrfs propose l’équivalent de la commande df, avec plus d’informations :
root@debian:~# btrfs filesystem df *filesystem*Pour obtenir plus de détails sur un système Btrfs, il faut utiliser la commande suivante :
root@debian:~# btrfs filesystem show *filesystem*Enfin, il est possible de défragementer un système Btrfs entier ou uniquement quelques fichiers avec la commande :
root@debian:~# btrfs filesystem defragment *[filesystem|files]*Les fonctionnalités implémentées
Conversion depuis Ext2/3/4
Btrfs possède très peu de métadonnées enregistrées à des emplacements fixes, ce qui facilite la conversion depuis d’autres systèmes de fichiers. La copie sur écriture autorise Btrfs à conserver une copie originale du système de fichier précédent, permettant ainsi à l’administrateur d’annuler la conversion même après avoir effectué des modifications dans le système Btrfs converti.
Btrfs possède un programme de conversion, btrfs-convert, qui lit les métadonnées de Ext4 et utilise l’espace libre d’Ext4 pour y implementer le nouveau système de fichier Btrfs.
Conversion
La convertion depuis Ext2/3/4 se déroule ainsi :
- duplication du premier méga-octet du disque ;
- duplication des répertoires et des inœuds, création des fichiers Btrfs ;
- création de références aux blocs de données d’Ext4 depuis les fichiers Btrfs.
Cette conversion engendre une copie de toutes les métadonnées d’Ext4, mais les fichiers Btrfs pointent seulement sur les mêmes blocs de données que les fichiers Ext4. Ainsi, l’utilisation d’une grande partie des blocs de données est partagée entre les deux système de fichiers. De plus, l’utilisation de la copie sur écriture permet la conservation de la version originale des fichiers d’Ext4.
Le premier méga-octet du disque est copié à un autre emplacement afin que les métadonnées Btrfs puissent y être écrites. Ainsi, lors de l’annulation de la conversion, une simple copie de ces fichiers à leur emplacement initial permettra de restaurer les métadonnées d’Ext4.
Le schéma suivant illustre l’organisation du disque après la conversion :
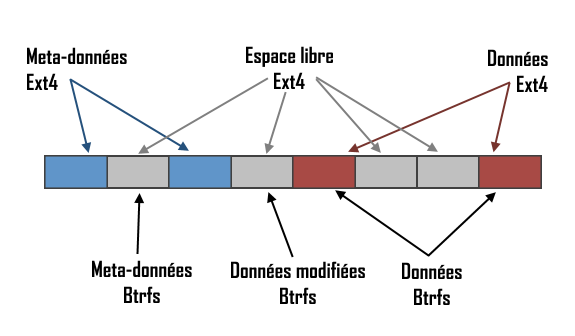
Utilisation
root@debian:~# btrfs-convert [-d] [-n] [-i] [-r] <dev>Definition des paramètres les plus fréquemment utilisés :
-ddésactive le calcul des sommes de contrôle de données. La conversion sera plus rapide.-ndésactive l’empaquettage des petits fichiers.-iignore les ACL (“Access Control List” : Gestion avancée des droits sous linux)-rpermet de revenir au système de fichier Ext2/3/4.
Redimmensionnement à chaud
Il est possible de redimmensionner les partitions Btrfs montées grâce à la commande suivante :
root@debian:~# btrfs filesystem resize <taille> /mnt/btrfsL’option taille doit être renseignée, et peut être utilisée de trois manières : en mettant + devant, pour agrandir la partition, - pour la diminuer, et enfin en spécifiant uniquement la taille finale souhaitée. Par exemple, pour réduire de 3 Go la partition :
root@debian:~# btrfs filesystem resize -3g /mnt/btrfsSous-volumes
Définition et principe
Un système de fichiers Unix classique contient une arborescence unique avec une seule racine. Par défaut, un système de fichiers Btrfs est organisé de la même façon. Les sous-volumes changent cette organisation en créant des racines alternatives qui fonctionnent comme des systèmes de fichiers indépendants ayant leurs propres droits.
Un sous-volume est traité par le système de fichier comme étant sur un support physique distinct. On peut ainsi le monter indépendament des autres sous-volumes et le traiter comme son propre système de fichiers. Il est tout à fait possible de créer toute une série de sous-volumes, monter chacun séparément et de se retrouver avec un ensemble de systèmes de fichiers indépendants partageant tous le même périphérique de stockage.
La racine du disque doit être montée pour pouvoir y créer des sous-volumes. Mais une fois ceux-ci créés, il est tout à fait possible de monter les sous-volumes sans avoir à monter la racine.
Un quota de blocs peut être affecté à un sous-volume. Une fois ce quota atteint, les nouvelles écritures ne sont plus autorisées.
Création et manipulations
root@debian:~# mkfs.btrfs /dev/sdb5
root@debian:~# mount /dev/sdb5 /mnt/1
root@debian:~# cd /mnt/1
root@debian:~# touch aNous avons donc un système de fichiers Btrfs classique contenant un seul fichier “a”. Nous pouvons à présent créer un sous-volume et y ajouter un fichier :
root@debian:~# btrfs subvolume create subv
root@debian:~# touch subv/b
root@debian:~# tree
.
├── a
└── subv
└── b
1 directory, 2 filesNous avons créé un sous-volume “subv” et nous y avons ajouté le fichier “b” en précisant qu’il devait se trouver dans ce sous-volume. Cette création ressemble très fortement à la création d’un répertoire “subv” dans lequel nous aurions placé le fichier “b”. Mais l’on constatera des différences lors de l’utilisation et de la manipulation des sous-volumes. Par exemple :
root@debian:~# ln a subv/
ln: failed to create hard link ‘subv/a’ => ‘a’: Invalid cross-device linkAinsi, même si le sous-volume ressemble à un répertoire ordinaire, il est traité par le système de fichier comme étant sur un support physique distinct. Se déplacer dans “subv” revient à traverser un point de montage Unix classique. Il est d’ailleurs possible de monter le sous-volume de façon indépendante :
root@debian:~# btrfs subvolume list /mnt/1
ID 257 gen 8 top level 5 path subv
root@debian:~# mount -o subvolid=257 /dev/sdb5 /mnt/2
root@debian:~# tree /mnt/2
/mnt/2
└── b
0 directories, 1 fileNormalement, Btrfs va monter la racine par défault à moins que nous lui disions de faire autrement avec l’option subvolid=<mount option>. Pour modifier le volume ou le sous-volume à monter par défaut, il faut utiliser la commande :
root@debian:~# btrfs subvolume set-default 257 /mnt/1Par la suite, monter /dev/sdb5 sans préciser d’options de montage avec subvolid=<mount option> reviendra à monter le sous-volume qui possède l’identifiant #257 (ici “subv”). Le volume racine possède l’identifiant #0.
Pour supprimer un sous-volume, il faut premièrement supprimer tous les fichiers qu’il contient, puis utiliser la commande suivante :
root@debian:~# btrfs subvolume delete <path>Compression
La compression permet de sauvegarder de l’espace disque, mais aussi de limiter les ralentissements causés par un disque dur trop lent (moins de données à transférer du disque dur vers la mémoire cache). Elle se fait de manière transparente lors de l’écriture et la lecture. Si la plupart du temps ces opérations n’impactent pas les performances de manière visible, il arrive que ce soit le cas. Par exemple, comme la compression se fait par bloc de données de 128 KiB, l’accès à un octet situé au milieu de ce bloc nécessitera la décompression de tout le bloc.
Implémentation dans Btrfs
Btrfs utilise actuellement deux algorithmes : ZLIB (par défaut) et LZO. Le premier est plus lent, mais compresse plus que LZO, qui a été conçu pour être rapide. La compression se fait en découpant les fichiers en morceaux de 128kb et en faisant traiter ces derniers par des threads, ce qui permet de diviser la charge de travail sur tous les CPUs même dans le cas d’un seul fichier. L’utilisation de la compression et le choix de la méthode se font simplement lors du montage de la partition :
root@debian:~# mount -o compress=lzo,zlib *dev* /mnt/btrfsTous les fichiers compressibles écrits après le montage se feront avec la méthode de compression choisie. Pour forcer la compression même sur les fichiers peu compressibles, il faut utiliser l’option compress-force. De plus, il est possible de compresser les fichiers déjà présents sur le volume grâce à la commande suivante :
root@debian:~# btrfs filesystem defragment -c zlib,lzoGestion des quotas
Définition et principe
Les quotas permmettent de fixer une limite d’utilisation des vlocs et ainsi répartir l’utilisation du support de stockage entre les différents utilisateurs, groupes et/ou sous-volumes.
La gestion des quotas dans Btrfs est implémentée au niveau des sous-volumes par l’utilisation de “groupes de quotas” (qgroup). Cette gestion n’étant pas présente depuis le début du développement de Btrfs, il est possible de scanner le système de fichier de sorte que les sous-volumes crées avant les gestion des quotas puissent en bénéficier. Dans ce sytème de quotas, chaque sous-volume est assigné à un qgroup de la forme 0/<ID du sous-volume>. Il est possible de créer un groupe de quotas identifié par un nombre quelconque mais l’ID du sous-volume est utilisé par défaut.
Activer les quotas
Activer les quotas sur un sous-volume Btrfs nouvellement créer se fait uniquement grâce à :
root@debian:~# btrfs quota enable <path>Sur un sous-volume existant, il faut d’abord activer les quotas et vérifier si la commande “``” retourne quelque chose. Si ce n’est pas le cas, alors Btrfs n’a pas créé automatiquement le qgroup et il va falloir le créer manuellement :
root@debian:~# btrfs quota enable <path>
root@debian:~# btrfs subvolume list <path> | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup create 0/{} <path>
root@debian:~# btrfs quota rescan <path>Gestion de volumes multiples
Btrfs implémente directement une gestion des volumes. Les différents volumes peuvent ainsi être organisés en RAID (Redundant Array Of Independant Disks) grâce différentes techniques permettant de répartir les données sur plusieurs disques durs de manière transparente pour l’utilisateur. Chaque type de RAID a pour but d’apporter une plus grande fiabilité (RAID 1), d’augmenter les performances en lecture/écriture (RAID 0), ou les deux (RAID 5, RAID 0+1, RAID 1+0), parfois au détriment d’autres facteurs (moins performant pour la reconstruction en cas de perte, nécessité de beaucoup de disque dur simultanément, etc.).
Pour le moment, Btrfs n’est officiellement stable que pour les RAID 0, 1 et 1+0, même si les RAID 5 et 6 sont déjà supportés. Nous allons donc rapidement présenter les RAID stables, avant de voir comment Btrfs implémente le RAID.
RAID 0
Le RAID 0 a pour but d’augmenter les performances et la capacité de stockage. Dans cette configuration, les données à écrire sont séparées en bandes (strip, d’où l’autre nom du RAID 0 : striping), chacune étant écrite sur un disque différent. Ainsi, s’il y a n disques, chacun d’entre eux ne devra écrire que 1/n des données, et la capacité totale de stockage sera de n fois celle du disque le plus petit. Voici un exemple avec deux disques :
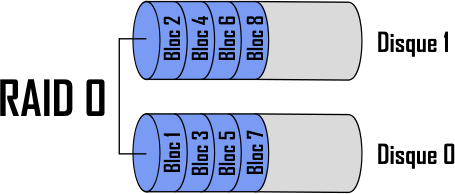
Ce RAID utilise tous l’espace de stockage (pas de redondance des données), ce qui le rend peu onéreux. Cependant, la perte d’un seul disque entraine la corruption de toutes les données.
RAID 1
Ce RAID repose lui aussi sur l’utilisation de n disques, mais cette fois-ci les données sont écrit de manière redondante sur chaque disque. Voici un exemple avec deux disques :
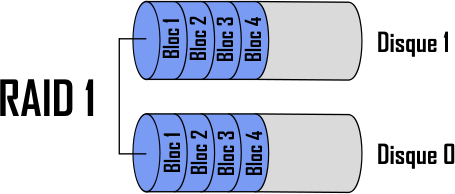
Cette méthode accepte une défaillance de n-1 disques, ce qui offre une très fiabilité. Cependant, elle est coûteuse en espace de stockage et n’améliore en rien les performances.
RAID 1+0
Ce RAID est la combinaison entre les deux RAID précédents. Les disques sont séparés en grappes RAID 1 d’au moins deux disques (donc il en faut au minimum 4). Les données sont écrites simultanément sur les différentes grappes selon la technique du RAID 0 ; au sein de chaque sous-grappe, elles sont écrites sur les différents disques de manière redondante (RAID 1). Voici un exemple avec quatre disques :
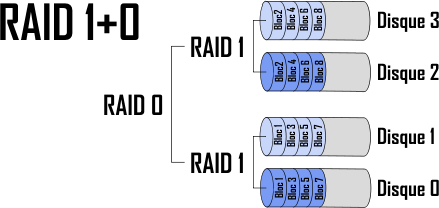
Cette technique regroupe les avantages des deux RAID précédents : rapidité d’écriture et fiabilité. Pour qu’une perte de données survienne, il faut que chaque grappe perde le même disque.
Implémentation dans Btrfs
L’implémentation des RAID dans Btrfs est classique. Cependant, Btrfs traite les données et les métadonnées séparément, et lors de la création d’un RAID il est possible d’indiquer un type de RAID (ou la non-utilisation du RAID) pour les données ou les métadonnées. Ainsi, il serait possible de stocker les données avec un RAID 0 (pour privilégier les performances) tout en utilisant un RAID 1 pour les métadonnées (dont la perte peut menacer l’intégrité du système tout entier). Cette stratégie de protection des métadonnées est aussi valable pour les systèmes sur un seul disque, où les métadonnées sont dupliquées pour parrer à la défaillance d’un secteur.
Le nombre de disques durs impliqués dans un RAID, ainsi que les paramètres de celui-ci (type de RAID, gestion des métadonnées, etc.) peuvent être changés à tout moment et à chaud, sans nécessiter de démontage du système. Les RAID nécessitant des nombres spécifiques de disques (par exemple le RAID 10) ne peuvent bien sûr n’être utilisés que lorsque les conditions sont satisfaites.
La commande pour créer un RAID est la suivante :
root@debian:~# mkfs.btrfs [-d mode] [-m mode] *dev1 dev2* ...C’est donc la même commande que pour créer un volume Btrfs, mais avec des options en plus. « -d mode » indique le mode de RAID pour les données ; « -m mode » celui pour les métadonnées. mode peut donc valoir raid0, raid1,raid10, ou un autre type de RAID implémenté mais non stable (raid5, raid6). La commande permettant de lister les disques impliqués dans le RAID est :
root@debian:~# btrfs filesystem show *dev*Pour ajouter ou supprimer le volume /dev/sdd1, il faut utiliser les commandes suivantes :
root@debian:~# btrfs device add /dev/sdd1 /mnt //ajout
root@debian:~# btrfs device delete /dev/sdd1 /mnt //suppression
root@debian:~# btrfs balance start -d -m /mnt //reconfiguration du RAID pour prendre en compte la modificationEnfin, la conversion peut s’effectuer sans démonter le système grâce à la commande suivante :
root@debian:~# btrfs balance start -dconvert=*mode* -mconvert=*mode* /mntComme btrfs doit copier beaucoup de données et recalculer toutes les sommes de contrôle correspondantes, l’opération peut prendre du temps. Enfin, btrfs est capable de reconnaitre de lui-même la présence d’un disque dur ne fonctionnant plus et peut monter le RAID en « mode dégradé » afin de pouvoir lancer les opérations de recouvrement des données et de ré-équilibrage du RAID :
root@debian:~# btrfs device delete missing /mnt/disque_defaillantInstantanés
Un instantanné est l’état du système à un moment donné. À l’inverse d’une sauvegarde, les données ne sont enregistrées que lorsque elles sont modifiées par le système actif. Si on veut se servir de cette méthode pour faire une sauvegarde totale du système, il convient donc de faire une sauvegarde traditionnelle préalablement, en copiant l’intégralité des données sur le suppprt de sauvegarde. Ensuite, à chaque prise d’instantanné, seules les données ayant été modifiées seront copiées, d’où une limitation de l’espace et des ressources utilisés.
Btrfs utilise la copie sur écriture pour gérer les instantannés. En effet, les données ne sont pas dupliquées par l’instantanné tant que le système de fichier actif ne les modifies pas, ce qui permet de diminuer l’espace disque utilisé.
Par exemple, juste avant que le système actif ne modifie la donnée D, voici la situation :
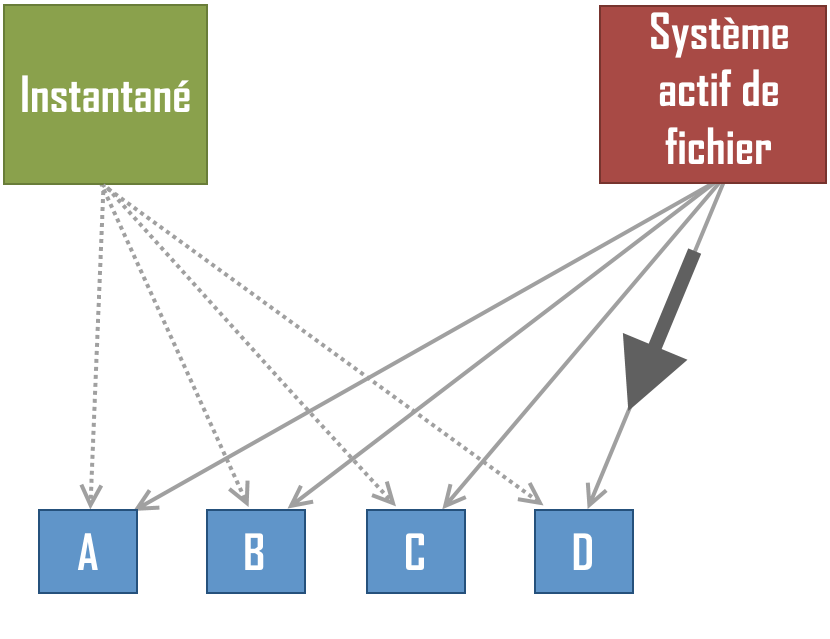
Puis le mécanisme de copie sur écriture créé une copie privée pour l’instantanné, et le système actif peut modifier la donnée sans que l’instantanné ne soit modifié :
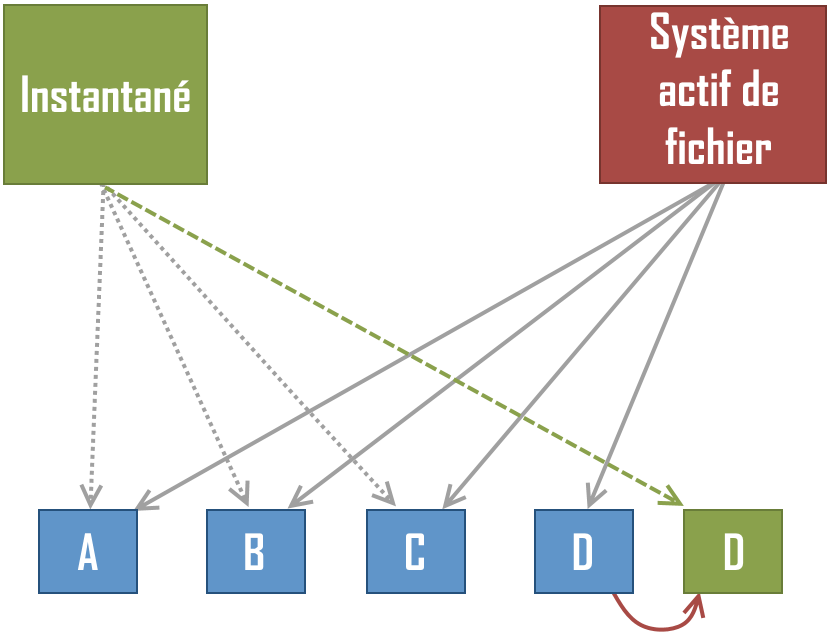
La création d’un instantanné se fait grâce à la commande suivante :
root@debian:~# subvolume snapshot *source* [*dest*/]*name*Les autres opérations de gestion d’un instantanné (suppression, défragmentation, quotas) se font de la même manière que pour un sous-volume classique.
Sommes de contrôles, vérifications et réparations
À la différence de Ext4, qui n’effectue des sommes de contrôle que sur les métadonnées, Btrfs en fait aussi sur les données. Cela permet de détecter à chaud les corruptions du système et donc de les corriger rapidement. Btrfs utilise l’algorithme crc32c pour les sommes de contrôles, qui sont vérifiées pour toutes les lectures et recalculées à chaque écritures. Comme pour la compression, les calculs sont séparés en threads afin de ne pas impacter les performances du système. De plus, elles peuvent être désactivées lors du montage avec l’option -o nodatasum. Les différentes sommes de contrôles (données, métadonnées) sont stockées séparément. En cas de détection d’erreur, Btrfs essaie tout d’abord de récupérer des copies valides (notamment en cas d’utilisation de RAID 1 ou 10), et sinon alerte l’utilisateur du problème.
Pour vérifier les sommes de contrôles de l’ensemble du système (opération souvent appelée scrub), il faut utiliser la commande btrfs scrub, par exemple :
root@debian:~# btrfs scrub start /mnt/btrfsIl est conseillé de lancer réguliérement cette commande pour détecter rapidement une défaillance. En cas d’erreurs, il existe la commande btrfsck ; cependant, celle-ci est récente et est déconseillée pour les données sensibles. Ainsi, avant de l’utiliser il convient d’essayer les commandes suivantes :
root@debian:~# btrfs rescue chunk-recover *dev*
root@debian:~# btrfs restore -l *dev*Btrfs : Installation & Démonstration
Afin de pouvoir expérimenter les diverses fonctionnalités de Btrfs, nous avons installé Debian sur une machine virtuelle.
Debian 7.7 Wheezy sur VirtualBox
Disque : 15 Go
sda1 Amorce Primaire ext4 298,85 Mo
sda5 NC Logique btrfs 13799,27 Mo
sda6 NC Logique swap 2004,88 Mo
Linux debian 3.2.0-4-amd64 #1 SMP Debian 3.2.63-2+deb7u1 x86_64 GNU/LinuxInstaller Debian 7.7 sur un système de fichiers Btrfs
Btrfs, bien qu’étant un système de fichier encore en développement, est intégré à l’image d’installation de Debian. Il suffit simplement de sélectionner Btrfs lors du partitionnement des disques.
/boot !
Les sous-volumes
Nous avons créé à la racine :
- Un fichier “
a” - Un répertoire “
subr” contenant un fichier “b” - Un sous-volume “
subv” contenant aussi un fichier “b”
root@debian:~# touch a
root@debian:~# btrfs subvolume create subv
Create subvolume './subv'
root@debian:~# touch subv/b
root@debian:~# mkdir subr
root@debian:~# touch subr/b
root@debian:~# tree
.
├── a
├── subr
│ └── b
└── subv
└── b
2 directories, 3 files
root@debian:~# ls -l
total 4
-rw-r--r-- 1 root root 24 nov. 12 19:22 a
drwxr-xr-x 1 root root 2 nov. 12 20:13 subr
drwx------ 1 root root 2 nov. 12 19:23 subvEnsuite, nous avons pu voir que même si le sous-volume apparait comme un répertoire, il n’en était pas un : test avec ln puis montage du sous-volume.
root@debian:~# ln a subv/
ln: impossible de créer le lien direct « subv/a » => « a »: Lien croisé de périphéque invalide
root@debian:~# ln a subr/
root@debian:~# tree
.
├── a
├── subr
│ ├── a
│ └── b
└── subv
└── b
2 directories, 4 files
root@debian:~# btrfs subvolume list subv/
ID 262 top level 5 path root/subv
root@debian:~# mount -o subvolid=262 /dev/sda5 /mnt/subv
root@debian:~# tree /mnt/subv/
/mnt/subv/
└── b
0 directories, 1 fileLes instantanés
Nous avons créé un sous-volume “subv” contenant un fichier “b” dans lequel nous avons écrit « Je suis le fichier “b” ». Puis nous avons pris un instantané (nommé subvSS)de ce sous volume grâce à la commande suivante :
root@debian:~# btrfs subvolume snapshot subv/ subvSS
Create a snapshot of 'subv/' in './subvSS'
root@debian:~# tree
.
├── a
├── subv
│ └── b
└── subvSS
└── b
2 directories, 3 filesLes fichiers “b” contenus dans “subv” et “subvSS” sont alors identiques. Note : Il est possible de déplacer et renommer l’instantané.
Nous avons ensuite modifié le fichier “subv/b” et lui avons ajouté une ligne de texte. Puis nous avons restauré l’instantané :
root@debian:~# cat subv/b
Je suis le fichier "b".
Je suis une modif faite après la snapshot !
root@debian:~# cat subvSS/b
Je suis le fichier "b".
root@debian:~# btrfs subvolume delete subv
Delete subvolume '/root/subv'
root@debian:~# btrfs subvolume snapshot subvSS/ subv
Create a snapshot of 'subvSS/' in './subv'
root@debian:~# btrfs subvolume delete subvSS
Delete subvolume '/root/subvSS'
root@debian:~# tree
.
├── a
└── subv
└── b
1 directory, 2 files
root@debian:~# cat subv/b
Je suis le fichier "b".La convertion Ext4/Btrfs
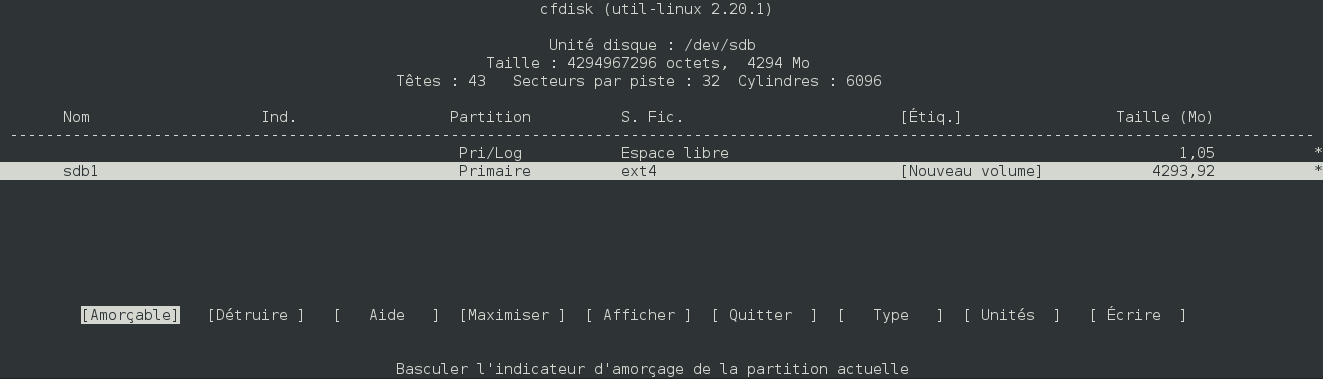
On considère le contenu suivant sur un disque (ici /dev/sdb1) :
root@debian:/mnt/test/ext4# tree
.
├── Bureau
├── Documents
│ ├── a
│ ├── b
│ └── c
├── Images
│ ├── d
│ ├── e
│ ├── f
│ └── g
├── Modèles
│ └── s
├── Musique
│ ├── h
│ └── i
├── Public
│ ├── o
│ ├── p
│ ├── q
│ └── r
├── Téléchargements
└── Vidéos
├── j
├── k
├── l
├── m
└── n
8 directories, 19 files
Nous avons ensuite démonté le volume, convertit puis remonté. Nous pouvons voir que la conversion s’est bien déroulée. Un instantané a aussi été créé au cas où nous voudrions revenir à Ext4 :
root@debian:~# umount /mnt/test/ext4/
root@debian:~# btrfs-convert /dev/sdb1
creating btrfs metadata.
creating ext2fs image file.
cleaning up system chunk.
conversion complete.
root@debian:~# mount /dev/sdb1 /mnt/test/btrfs/
root@debian:~# cd /mnt/test/btrfs/
root@debian:/mnt/test/btrfs# tree
.
├── Bureau
├── Documents
│ ├── a
│ ├── b
│ └── c
├── ext2_saved
│ └── image
├── Images
│ ├── d
│ ├── e
│ ├── f
│ └── g
├── Modèles
│ └── s
├── Musique
│ ├── h
│ └── i
├── Public
│ ├── o
│ ├── p
│ ├── q
│ └── r
├── Téléchargements
└── Vidéos
├── j
├── k
├── l
├── m
└── n
9 directories, 20 files
root@debian:/mnt/test/btrfs# btrfs sub list ext2_saved/
ID 256 top level 5 path ext2_saved
Nous avons fait des moficications sur le disque, puis nous avons reconvertit le disque en Ext4 :
root@debian:/mnt/test/btrfs# mv Documents/a Musique/a
root@debian:/mnt/test/btrfs# mv Public/* Téléchargements/
root@debian:/mnt/test/btrfs# rm Vidéos/k
root@debian:/mnt/test/btrfs# touch Documents/z
root@debian:/mnt/test/btrfs# tree
.
├── Bureau
├── Documents
│ ├── b
│ ├── c
│ └── z
├── ext2_saved
│ └── image
├── Images
│ ├── d
│ ├── e
│ ├── f
│ └── g
├── Modèles
│ └── s
├── Musique
│ ├── a
│ ├── h
│ └── i
├── Public
├── Téléchargements
│ ├── o
│ ├── p
│ ├── q
│ └── r
└── Vidéos
├── j
├── l
├── m
└── n
9 directories, 20 files
root@debian:~# umount /mnt/test/btrfs/
root@debian:~# btrfs-convert -r /dev/sdb1
rollback complete.
root@debian:~# mount /dev/sdb1 /mnt/test/ext4/
root@debian:~# cd /mnt/test/ext4/
root@debian:/mnt/test/ext4# tree
.
├── Bureau
├── Documents
│ ├── a
│ ├── b
│ └── c
├── Images
│ ├── d
│ ├── e
│ ├── f
│ └── g
├── Modèles
│ └── s
├── Musique
│ ├── h
│ └── i
├── Public
│ ├── o
│ ├── p
│ ├── q
│ └── r
├── Téléchargements
└── Vidéos
├── j
├── k
├── l
├── m
└── n
8 directories, 19 filesBenchmark, mesures de performances
L’efficacité d’un système de fichiers peut se mesurer à sa réactivité lors d’opération de lecture, d’écriture. Selon l’utilisation qu’aura la machine le type d’utilisation du système de fichiers varie. Par exemple pour un serveur proxy ou un serveur web, le système devra lire/écrire de très nombreux petits fichiers, créer des arborescences parfois très complexes. Les accès vont se faire aléatoirement, on mesure alors les débits en lecture/écriture aléatoire.
En revanche, dans le cas du stockage d’archives, de films, images système, … les fichiers deviennent vite très volumineux, le débit de lecture/écriture est alors le plus important. Pour ce type d’utilisation on mesurera les accès séquentiels.
Nous nous baserons sur des bench récupérés en partie sur openbenchmarking.org.
Performance des différents modes de RAID
Basé sur : http://openbenchmarking.org/result/1411054-LI-BTRFSRAID55
Test de débits séquentiels
Les tests de lecture ont échoués en partie, mais on peut voir que l’implémentation du RAID 6 de btrfs est assez performante (environ 15% plus rapide en écriture). Plus globalement btrfs se démarque bien en écriture, dans toutes les configurations exceptées en RAID 0. En plus de n’être déjà pas très bon avec mdadm pour gérer le RAID 0, les performances en écriture se dégradent encore quand on utilise la gestion native du RAID 0.
Test de débits aléatoires
Ici encore on peut voir que le RAID 0 natif de btrfs souffre encore de quelques lacunes par rapport à celui de mdadm en lecture, mais étonnamment le débit d’écriture est le meilleur relevé. Contrairement aux tests en séquentiel, le RAID 6 natif de btrfs donne les pires performances du comparatif en lecture aléatoire, avec un écart de près de 25% par rapport au concurrent suivant qui est le système de fichiers que btrfs est sensé remplacer. Heureusement, couplé à mdadm il décroche la troisième place.
Le RAID 10 n’est pas non plus à son avantage mais reste devant XFS de 20%, et laissant mdadm gérer le RAID, on retrouve des performances équivalentes à ext4.
Pour ce qui est des RAID 5 et 1, toutes les configurations sont à peu près équivalentes. Du coté de l’écriture aléatoire donne les meilleurs résultats avec btrfs, et ce quelque soit la configuration.
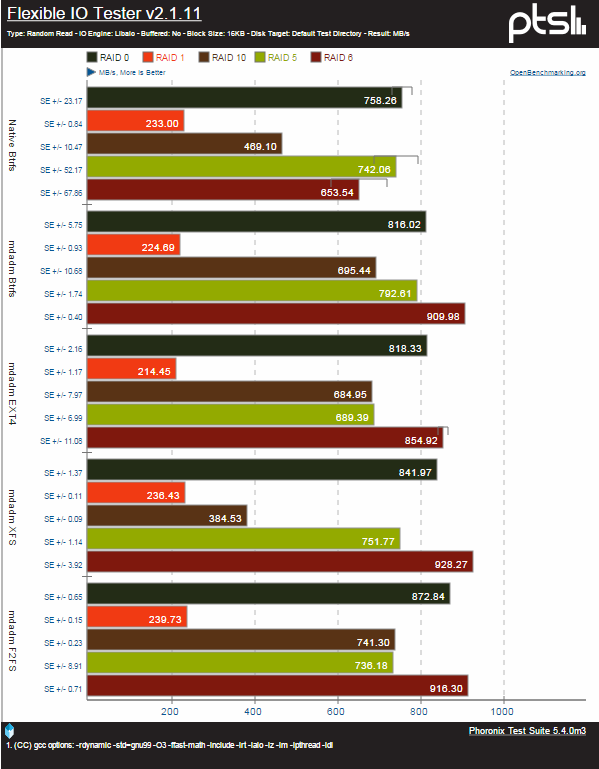
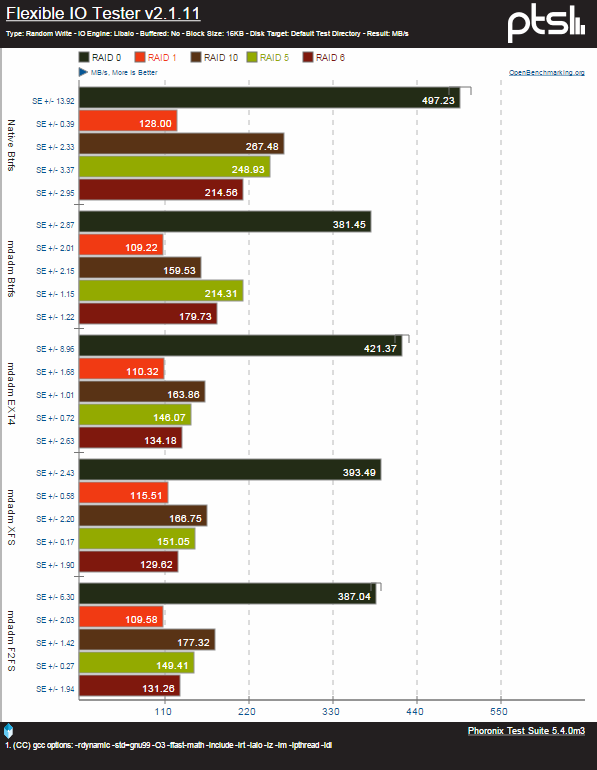
Basé sur : http://openbenchmarking.org/result/1102238-IV-1102232IV10 et http://openbenchmarking.org/result/1203144-BY-UBUNTUFS745
Depuis le premier benchmark (noyau 2.6) on peut voir clairement que btrfs a bien progressé. Lors du premier ses performances étaient bien en dessous de celles d’ext4, alors qu’on peut voir que dans le plus récent des bench, btrfs est beaucoup plus souvent au même niveau qu’ext4. On peut donc espérer que ses performances continueront d’augmenter pour arriver à dépasser largement celles d’ext4.
Conclusion
Bien que lancé en même temps que ZFS, le projet Btrfs est moins avancé, les développeurs s’étant aussi concentrés sur Ext4. Cependant, la base est déjà stable, et de nouvelles fonctionnalités sont arrivées récemment et promettent de devenir stables d’ici peu. Ainsi, Btrfs offre déjà la plupart des fonctions des systèmes de fichiers « nouvelles générations » (gestion des gros volumes et des gros fichiers, sous-volumes, instantannés, compression, RAID, etc.) de manière native tout en étant fiable.
Si pour le moment les performances sont légérement en deça de ce qui peut être trouvé sur les autres systèmes de fichiers, nous pouvons constater des améliorations à chaque mises à jour. Le développement est encore actif et est dans une phase de stabilisation du code, nous pouvons donc espérer que Btrfs puisse bientôt concurrencer les autres systèmes de fichiers dans le domaine des performances, ce qu’il fait déjà pour ce qui concerne les fonctionnalités.
L’actualité montre une accélération de l’adoption de Btrfs. Des entreprises en proposent le support, d’autres (telle que Facebook) ont commencé à tester et à mettre en prodution le système de fichier. Au fur et à mesure que l’usage se répand, le nombre de contributeurs et de testeurs augmente aussi et laisse présager un cercle vertueux qui aménerait la stabilité totale et à terme la maturité du projet. Ainsi, si nous ne pouvons le conseiller à des entreprises stockant des données sensibles et ne souhaitant pas perdre de temps à cause de la technologie utilisée, nous encourageons toute société voulant rester à la pointe à tester Btrfs, et pourquoi pas à l’adopter en production.
Sources et références
- (
en) btrfs.wiki.kernel.org - (
en) The Btrfs filesystem sur lwn.net - (
en) A short history of Btrfs sur lwn.net - (
en) How I Use the Advanced Capabilities of Btrfs sur oracle.com - (
fr) ZFS et Btrfs, systèmes de fichiers ultimes à l’heure des big data? - (
en) Ext4, btrfs, and the others - (
en) Workload Dependent Performance Evaluation of the Btrfs and ZFS Filesystems - (
en) Btrfs sur wikipedia.org - (
en) My Btrfs Talk at Linuxcon JP 2014
Recherches & rédaction : Jake, Wandrille et Thom
 Cet article est mis à disposition selon les termes de la Licence Creative Commons Attribution-ShareAlike 4.0 International.
Cet article a été publié il y a 1996 jours, son contenu peut être inexact, voire erroné, et l'application des conseils ou consignes présents dans cet article doit être fait à votre propre appréciation. L'auteur de l'article ne pourra être tenu responsable des inconvénients pouvant résulter de l'application des conseils et consignes énoncés dans cet article.
Cet article est mis à disposition selon les termes de la Licence Creative Commons Attribution-ShareAlike 4.0 International.
Cet article a été publié il y a 1996 jours, son contenu peut être inexact, voire erroné, et l'application des conseils ou consignes présents dans cet article doit être fait à votre propre appréciation. L'auteur de l'article ne pourra être tenu responsable des inconvénients pouvant résulter de l'application des conseils et consignes énoncés dans cet article.




Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email